무더웠던 날씨가 슬슬 선선해지고 있어요!
끈적한 날씨 때문에 공부하기 힘들다고 생각했던 게 엊그제 같은데 벌써 15주차가 되었습니다.
아무리 힘들어도 한 걸음씩 나아가다 보면 지금보다 나아질 거라는 생각에 자신감이 생겨요 ^_^
일체가 된 것처럼 과정 속에 온전히 몰입하고 나면 늘 개운한 감정이 남는데, 이 기분은 언제 느껴도 좋습니다!
LLM 담당 강사님께서 이 과정을 잘 안내해 주셔서 정말 감사했어요.
나중에 기회가 생기면 또 뵙고 싶다는 생각이 들었을 정도로 마지막 수업이 아쉽게 느껴졌습니다.
강사님께서 인프런 강의도 운영하시는 걸로 알아서 그걸로 적적한 마음을 달래보려구요...
혹시 관심 있으신 분들은 아래 접은 글에 강사님 강의 링크를 첨부했으니 참고하시길 바랍니다!
+) Low level 동작 원리를 기반으로 C, Linux, Python 오픈 소스를 분석하고 싶으신 분들께 추천드립니다. 향후에 딥러닝 소스 분석 강의 위주로 더 내실 예정이라니까 많은 관심 부탁드려요!
엔코아 및 SK 네트웍스 관계자 분들께서 좋은 강사님을 소개해 주신 덕분에 많이 배울 수 있었습니다.
다음 수업부터는 웹에 특화되신 강사님이 오실 예정이라는데 어떤 분이실지 정말 궁금해요.
벌써부터 두근두근거립니다~ 이번에도 알차게 배워야지~~!

● 성취
이번 주간에는 미니 프로젝트가 있었어요.
'RAG를 활용한 LLM 챗봇'라는 큰 주제 하에 자유롭게 세부 주제를 정할 수 있었습니다.
저희 팀은 'Smart Manual : QR로 만나는 AI 사용설명서'를 세부 주제로 정했어요.
일주일도 안 될 정도로 준비 기간이 짧았기 때문에 적절한 전략 선택이 중요하다고 판단했습니다.
따라서 저희는 데이터 전처리가 복잡하지 않으면서, RAG(Retrieval-Augmented Generation) 기술 응용이 절실한 분야를 찾기로 했습니다.
RAG은 기존 LLM의 언어 능력에 외부 DB 지식을 결부시킴으로써 대답의 신뢰성을 확보할 수 있습니다.
이를 통해 LLM의 언어능력을 활용하는 동시에 LLM 특유의 헛소리(=할루시네이션, hallucination)를 줄일 수 있습니다.
RAG는 위와 같은 특성이 있기 때문에, 읽기 귀찮지만 차마 버릴 수 없는 '상품 가이드' 같은 문서를 대상으로 설정하는 것이 적절하다고 생각했습니다.
또한 상품 가이드는 타 문서에 비해 비교적 짧은 길이에 속하기 때문에, 데이터 전처리 과정을 검토하기에도 덜 복잡할 것이라 판단했습니다.
따라서 저희는 'SK매직 무전원 직수 정수기 WPU-GBC112 : 제품 설명서'를 대상으로 RAG 기법을 적용하기로 결정했습니다.

저희 팀이 제작한 프로그램의 아키텍처는 위 그림과 같습니다.
주요 도구로는 Streamlit, Langchain, Chroma DB, OpenAI LLM을 이용했습니다.
사용자가 스마트 매뉴얼 QR 코드를 통해 Streamlit 기반 사이트로 이동하면, 가이드 챗봇에게 질문을 남길 수 있도록 설정했습니다.
사용자가 남긴 질문은 Langchain에 쿼리로 입력됩니다. 이러한 쿼리를 기반으로 RAG 시스템에서 사용자가 찾으려는 내용과 유사한 문서를 찾을 수 있습니다.
여기서 찾은 문서 내용들은 '사용자 쿼리'와 '사전 정의한 프롬프트 명령문 템플릿'과 결합하여 더 정교한 형태의 질문을 만들 수 있어요.
이렇게 만들어진 질문을 'OpenAI : gpt-4o mini' LLM 모델에 입력하여 대답을 받아낼 수 있습니다.
마지막으로 LLM에서 생성한 대답을 Streamlit에 띄웁니다.
이로써 사용자가 제품 설명서에서 궁금했던 내용을 GUI 기반 채팅 형태로 받을 수 있습니다!

이런 식으로 제품 설명서를 챗봇 형태로 이용할 수 있어요.

그리고 위 예시처럼 정수기와 연관 없는 내용을 물어보면 답변할 수 없다고 말하도록 설정했습니다.
RAG 기능을 이용했기 때문에 제품 설명서와 연관 없는 내용은 응답할 수 없도록 가이드하는 게 가능했답니다 ^_^
원했던 시나리오처럼 동작해서 상당히 만족스러웠어요.
이번 팀플을 통해 팀원들(선아 언니, 종호, 정원)에게 많이 배울 수 있었어요!
제가 팀 리더라고 말하는 게 부끄러웠을 정도로 다들 열심히 참여했기 때문에 의미 있는 프로젝트 결과물을 남길 수 있었어요.
팀 리더/팔로워를 나누는 것이 무색할 정도로 모든 사람들이 유연한 자세로 열정적으로 참여한 팀 프로젝트였습니다!
다들 정말 수고했습니다~~!!
이번 주에는 RAG 미니 팀 프로젝트 경험이 제게 가장 큰 성취였습니다!!
● 학습
이번 주에는 Pytorch 공식 문서를 기반으로 '오디오 데이터 처리 방식'에 대해 배웠습니다.
오늘은 여러 코드들 중에서 가장 흥미롭다고 느꼈던 'Audio Data Augmentation'에 대해 소개하겠습니다!
AI를 다루다 보면 '데이터 확보'가 중요하다는 것을 알 수 있는데요.
데이터 확보를 위해 많이 사용하는 기법 중 하나가 바로 'Data Augmentation'입니다.
정형 데이터, 이미지 데이터 등은 Data Augmentation을 적용해 본 경험이 있지만, 오디오 데이터에서는 이번이 처음이라 생소한 내용이 많았습니다...^^
그럼 차근차근 설명해보겠습니다!
• 중심 라이브러리 설정하기
import torch
import torchaudio
import torchaudio.functional as F
print(torch.__version__) # 2.3.1+cu121
print(torchaudio.__version__) # 2.3.1+cu121
import matplotlib.pyplot as plt
먼저 위 코드를 실행해서 필요한 중심 라이브러리 환경을 구축해 주세요.
• 필요한 음원 자료 다운받기
from IPython.display import Audio
from torchaudio.utils import download_asset
SAMPLE_WAV = download_asset("tutorial-assets/steam-train-whistle-daniel_simon.wav")
SAMPLE_RIR = download_asset("tutorial-assets/Lab41-SRI-VOiCES-rm1-impulse-mc01-stu-clo-8000hz.wav")
SAMPLE_SPEECH = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042-8000hz.wav")
SAMPLE_NOISE = download_asset("tutorial-assets/Lab41-SRI-VOiCES-rm1-babb-mc01-stu-clo-8000hz.wav")
Data Augmentation을 수행하기 위해서 data는 필수적입니다.
다행스럽게도 Pytorch에서는 연습용 오디오 데이터를 제공합니다.
위 코드를 동작시키면 Pytorch에서 제공하는 오디오 파일을 다운로드할 수 있습니다!
• 간단하게 이펙트 및 필터링 효과 적용시켜 보기
# Load the data
waveform1, sample_rate = torchaudio.load(SAMPLE_WAV, channels_first=False)
# Define effects
effect = ",".join(
[
"lowpass=frequency=300:poles=1", # apply single-pole lowpass filter
"atempo=0.8", # reduce the speed
"aecho=in_gain=0.8:out_gain=0.9:delays=200:decays=0.3|delays=400:decays=0.3"
# Applying echo gives some dramatic feeling
],
)
# Apply effects
def apply_effect(waveform, sample_rate, effect):
effector = torchaudio.io.AudioEffector(effect=effect)
return effector.apply(waveform, sample_rate)
waveform2 = apply_effect(waveform1, sample_rate, effect)
print(waveform1.shape, sample_rate) # torch.Size([109368, 2]) 44100
print(waveform2.shape, sample_rate) # torch.Size([144642, 2]) 44100
샘플 wav 음성 파일에 효과를 적용합니다.
여기서 지정한 효과는 '저주파 강조 + 기존보다 살짝 느린 속도 + 에코 부여'입니다.
apply_effect 함수를 적용하면 음성 데이터 역시 변합니다.
waveform1(효과 적용 전)과 waveform2(효과 적용 후)에 출력하는 shape 형태만 봐도 알 수 있겠지요?
• 시각화 함수 정의하기 (waveform : 파형, specgram : 스펙트로그램)
# Draw waveform plots
def plot_waveform(waveform, sample_rate, title="Waveform", xlim=None):
waveform = waveform.numpy()
num_channels, num_frames = waveform.shape
time_axis = torch.arange(0, num_frames) / sample_rate
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].plot(time_axis, waveform[c], linewidth=1)
axes[c].grid(True)
if num_channels > 1:
axes[c].set_ylabel(f"Channel {c+1}")
if xlim:
axes[c].set_xlim(xlim)
figure.suptitle(title)
# Draw spectrogram plots
def plot_specgram(waveform, sample_rate, title="Spectrogram", xlim=None):
waveform = waveform.numpy()
num_channels, _ = waveform.shape
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].specgram(waveform[c], Fs=sample_rate)
if num_channels > 1:
axes[c].set_ylabel(f"Channel {c+1}")
if xlim:
axes[c].set_xlim(xlim)
figure.suptitle(title)
plot_waveform 함수를 사용하면 파형을 시각화할 수 있습니다.
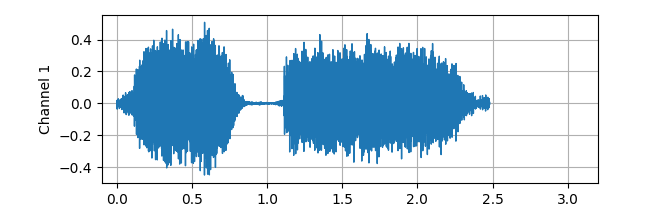
그러면 이런 식으로 파형을 눈으로 볼 수 있어요! 우리가 잘 알고 있는 음성 파일 형태이지요?
plot_specgram 함수를 사용하면 스펙트로그램(spectrogram) 형태로 시각화할 수 있습니다.
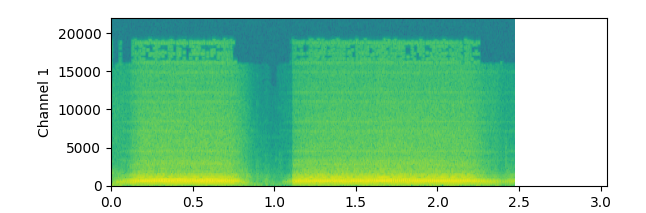
약간 생소하게 생겼지요...?
스펙트로그램은 x축은 시간을, y축은 주파수를, z축은 진폭을 나타냅니다.
파형과 스펙트럼이 합쳐진 형태로, 푸리에 변환과 연계해서 많이 쓰이는 오디오 데이터 시각화 방식입니다.
• 실내 음향 선명하게 만들기
rir_raw, sample_rate = torchaudio.load(SAMPLE_RIR)
plot_waveform(rir_raw, sample_rate, title="Room Impulse Response (raw)")
plot_specgram(rir_raw, sample_rate, title="Room Impulse Response (raw)")
Audio(rir_raw, rate=sample_rate)
RIR 샘플 데이터를 가져옵니다.
참고로 RIR (Room Impulse Response)는 특정 공간 및 환경과 음성 간의 상호작용을 분석을 기반으로 더 나은 음성 변환법 탐색을 목적으로 합니다.
rir = rir_raw[:, int(sample_rate * 1.01) : int(sample_rate * 1.3)]
rir = rir / torch.linalg.vector_norm(rir, ord=2)
plot_waveform(rir, sample_rate, title="Room Impulse Response")
speech, _ = torchaudio.load(SAMPLE_SPEECH)
augmented = F.fftconvolve(speech, rir)
여기서는 RIR 샘플 데이터의 1.01초~1.3초 부분만 떼어낸 후 정규화를 합니다.
이를 통해 원본 데이터에 비해 선명한 음성을 추출할 수 있습니다.
+) augmented는 원본에 비해 살짝 울리는 감이 있지만, 소리 자체는 좀 더 선명해지긴 했습니다!
plot_waveform(speech, sample_rate, title="Original")
plot_specgram(speech, sample_rate, title="Original")
Audio(speech, rate=sample_rate)
plot_waveform(augmented, sample_rate, title="RIR Applied")
plot_specgram(augmented, sample_rate, title="RIR Applied")
Audio(augmented, rate=sample_rate)
이 코드를 동작시키면 Data Augmentation 전후 차이를 확인할 수 있습니다!
소리도 들을 수 있어요~
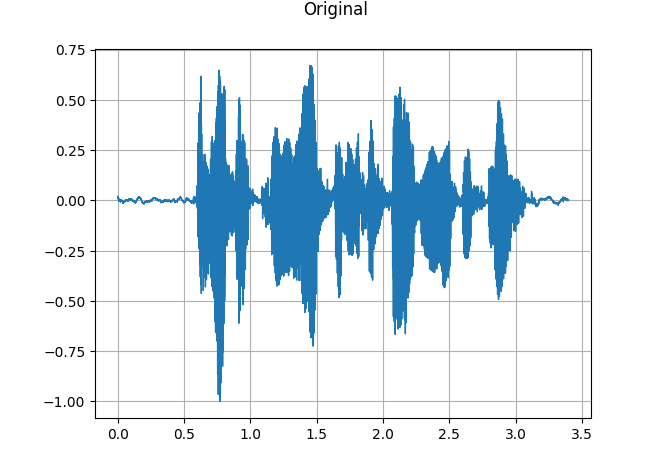
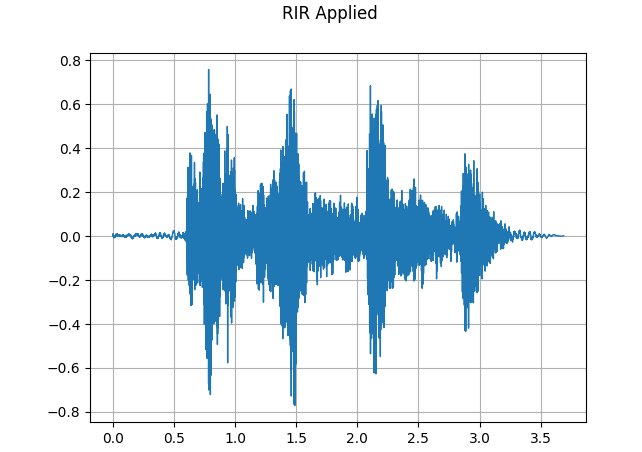
파형 이미지만 봐도 전/후 차이가 확 보이지요?
이게 바로 Audio Data Augmentation입니다!
새로 알게 된 분야여서 정말 흥미로웠어요 ^_^
● 개선
미니 팀 프로젝트에 임하기 전, 수업시간에 다뤘던 RAG 코드를 복습했습니다!
기본기 충실하게 복습해야 실전에서 흔들림이 덜 하더라구요.
후회 없는 선택이었습니다! 👍
개인적으로 저는 '3-step 공부법'을 좋아합니다.
- 예제 코드를 동작시키면서 기본 방식을 이해한다.
- 도메인을 살짝 바꿔서 예제 코드에 적용해 본다. (예제에서 A가 대상이었다면, 저는 B로 시도해 봅니다.)
- 예제 코드 기반으로 실전 프로젝트를 뛰어 본다.
이 과정이 귀찮게 느껴질 수 있더라도 하다 보면 다른 방법보다 실력이 빠르게 붙더라구요!
그래서 저는 이 방법으로 코드 공부하는 것을 정말 좋아해요 :)
1번은 수업에서 했으므로, 저는 2번 방식에 충실하게 복습을 했습니다.
3번은 미니 프로젝트에서 할 예정이라 생각이 들어서 일단 보류했구요. (결국에는 3번까지 성공적으로 완수했습니다!)
오늘은 2번 방식으로 복습했던 RAG 코드를 설명해 볼게요!
+) 저는 이번에도 환경 관리 비용을 줄이고자 Colab을 사용했습니다...^^
# 라이브러리 설치하기
!pip install langchain openai chromadb langchainhub tiktoken!pip install -U langchain-community
위 라이브러리들을 설치해 주세요~
langchain 기반으로 RAG 시스템을 구축할 때 필요한 라이브러리들입니다!
# OpenAI : API Key 설정하기
OPENAI_KEY = "개인Key를 입력하세요"
OpenAI에서 개인 API Key를 발급받으신 후에 꼭 입력해 주세요!
개인 프로젝트 용도로 쓰는 사람들은 생각보다 비용이 많이 안 나간답니다...^^
# 웹 페이지 로드 및 정제하기
from langchain.document_loaders import WebBaseLoader
# 웹 페이지 불러오기
loader = WebBaseLoader("https://www.aitimes.com/news/articleView.html?idxno=162796")
pages = loader.load_and_split()
# 불러온 내용을 작은 chunk 단위로 나누기
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
splits = text_splitter.split_documents(pages)
저는 AI 타임즈의 '이용자 낚시 챗봇' 관련 기사에 흥미가 생겨서 해당 자료를 가져왔어요!
불러온 자료는 작은 chunk 단위로 나눠 줌으로써 데이터 전처리를 진행합니다.
# 벡터 DB에 데이터 저장하기
# OpenAI Embedding 모델을 이용해서 Chunk를 Embedding 한후 Vector Store에 저장
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(openai_api_key=OPENAI_KEY)) # text-embedding-ada-002
retriever = vectorstore.as_retriever(search_kwargs={'k':10})
전처리를 마친 데이터에 임베딩 과정을 수행해 주세요.
임베딩이 끝난 데이터는 Chroma DB(벡터 DB 종류 중 하나)에 집어 넣습니다.
그리고 retriever를 사용해서 연관 자료를 꺼내 올 때 몇 개를 참고할 건지 k 값에 입력해 주세요.
저는 10개를 참고하기로 했습니다...^^
# 결과문 parser 정의하기
from langchain.schema import BaseOutputParser
class OutputParser(BaseOutputParser):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str):
"""Parse the output of an LLM call."""
return text.strip().split("\n")
langchain 라이브러리 속 BaseOutputParser를 상속 받아서 결과문을 어떻게 parsing할 것인지 정의해 줍니다.
저는 '\n'을 기준으로 파싱하기로 했습니다~!
# 프롬프트 템플릿 정의하기
from langchain.prompts import PromptTemplate
template = """다음과 같은 맥락을 사용하여 마지막 질문에 대답하세요.
친절한 말투로 단계별로 답변하세요.
절대 답을 지어내려고 하지 마세요.
항상 '질문해주셔서 감사합니다!'라고 답변 끝에 말하세요.
{context}
질문: {question}
도움이 되는 답변:"""
rag_prompt_custom = PromptTemplate.from_template(template)
자, 다음으로 프롬프트 템플릿을 정의해 줍니다!
프롬프트 템플릿을 통해 LLM 챗봇에게 컨셉을 정해줄 수 있어요.
저는 정직하면서도 친절한 챗봇 컨셉으로 선택했습니다~
# 사용 LLM 지정하기
from langchain.chat_models import ChatOpenAI
# GPT-4o mini를 이용해서 LLM 설정
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, openai_api_key=OPENAI_KEY)
저는 GPT-4o mini를 사용 LLM으로 지정했습니다.
다른 모델 사용하실 분들은 https://platform.openai.com/docs/models 여기서 다른 모델 이름을 찾아보신 후에 넣으시면 됩니다~
잘 모르시는 분들은 그냥 'GPT-4o mini' 사용하시는 걸 추천합니다!
2024.08 기준으로 이게 성능 대비 가격이 저렴한 편이더라구요.
# RAG 용도의 chain 설정하기
from langchain.schema.runnable import RunnablePassthrough
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | rag_prompt_custom | llm | OutputParser()
| 이렇게 보이는 걸 '파이프 연산자'라고 하는데요.
이걸 사용하면 사용자가 원하는 대로 chain을 커스텀하기 좋습니다.
저는 파이프 연산자를 통해 필요한 부품들을 모아서 rag 용도의 chain을 구성해 줬습니다.
+) 참고로 파이프 연산자는 유닉스 운영체제에서도 많이 쓰인다고 합니다!
# RAG 시스템에게 질문하기
txt = "릭롤이 뭔가요?"
print(*rag_chain.invoke(txt), sep='\n')
print('\n')
print(retriever.get_relevant_documents(txt))
# 릭롤(RickRoll)은 인터넷에서 유행하는 장난으로, 사용자가 클릭할 것으로 예상되는 링크를 클릭했을 때, 실제로는 팝 가수 릭 애슬리(Rick Astley)의 1987년 히트곡 "Never Gonna Give You Up"의 뮤직비디오로 연결되는 것을 말합니다. 이 장난은 2007년 게임 '그랜드 시프트 오토 4'의 트레일러가 화제가 되었을 때 시작되었으며, 이후 인터넷 밈으로 자리 잡았습니다.
# 1. **링크 클릭 유도**: 사용자가 흥미를 가질 만한 링크를 제공하여 클릭하도록 유도합니다.
# 2. **비디오 재생**: 클릭한 후, 예상과는 다른 뮤직비디오가 재생되며 사용자는 당황하게 됩니다.
# 3. **유행**: 이 장난은 시간이 지나도 여전히 종종 사용되며, 많은 사람들에게 익숙한 유머로 남아 있습니다.
# 릭롤은 단순한 농담이지만, AI 챗봇과 같은 시스템이 이를 잘 구분하지 못하는 경우가 있어, 최근에는 AI 챗봇이 사용자에게 엉뚱한 링크를 제공하는 사례도 발생하고 있습니다.
# 질문해주셔서 감사합니다!
# [Document(metadata={'description': "미국의 한 스타트업이 제작한 인공지능(AI) 챗봇이 사용자를 '릭롤(RickRoll)'하는 일이 발생했다. 이는 구글의 AI 검색처럼 (중략)")]
위에서 구축한 RAG 시스템에게 '릭롤이 뭔가요?'라고 질문을 남겼습니다.
결과를 보니 챗봇이 기사 속 내용을 요약해서 잘 말하고 있습니다!
+) Document 출처 결과는 너무 길어서 제가 일부러 살짝 생략했습니다.
아무래도 '릭롤'은 미국에서 유행하는 인터넷 장난을 의미하나 봅니다.
RAG 시스템을 잘 이용하면 어렵고 복잡한 문서도 채팅 형태로 이해하기 좋을 것 같다는 생각이 들었습니다.
물론 이 자료는 어렵게 쓰인 글이 아니지만, 활용 가능성이 무궁무진해 보여요!
역시 AI와 딥러닝 세계는 늘 흥미롭고 재밌습니다....^_^
LLM 단원이 끝나서 아쉽지만... 다른 것들도 공부해야지요!
LLM 강사님, 그동안 정말 감사했습니다! 짧은 시간이지만 덕분에 정말 많은 것들을 배웠습니다!

새로운 선생님과 함께 앞으로 진행될 웹 수업도 정말 기대되네요!
미리 잘 부탁드리겠습니다~~!!!
+) 부족한 부분이 있으면 댓글로 말씀해 주세요! 겸허한 마음으로 더 공부하겠습니다.
'활동 > SK네트웍스 Family AI 캠프 2기' 카테고리의 다른 글
| SK네트웍스 Family AI 캠프 2기 : 17th week (9월 1주차) (4) | 2024.09.09 |
|---|---|
| SK네트웍스 Family AI 캠프 2기 : 16th week (8월 5주차 + 8월 회고) (10) | 2024.09.02 |
| SK네트웍스 Family AI 캠프 2기 : 14th week (8월 3주차) (0) | 2024.08.19 |
| SK네트웍스 Family AI 캠프 2기 : 13th week (8월 2주차) (0) | 2024.08.12 |
| SK네트웍스 Family AI 캠프 2기 : 12th week (8월 1주차) (1) | 2024.08.05 |



