벌써 입추가 지났어요.
확실히 입추를 넘기니까 어느 정도 견딜 수 있는 날씨가 된 것 같습니다.
곧 다가올 수확 시기처럼... 제 실력도 잘 영글어서 현업에 기여할 수 있는 경지에 도달하면 좋겠어요!
농부의 마음에 이입하면서 과정에 충실하게 임해야겠습니다 :)

● 성취 & 학습
이번 주에는 수업 자료 보충에 있어서 여러 기여를 했다고 생각합니다!
이러한 기여 과정 속에서 성취감과 학습 효과를 동시에 얻었기 때문에 묶어서 설명하려고 합니다 :)
# langchain 10번 예제 코드 수정
langchain 10번 예제 코드는 '요약 판결문 데이터를 사용한 RAG(Retrieval-Augmented Generation) 구현 코드'였습니다.
해당 코드는 다음과 같은 처리 과정을 거쳤는데요.
- 판결문 데이터 불러온 후에 Chat-GPT api 사용해서 요약하기
- 요약한 판결문 데이터를 임베딩한 후, 벡터DB에 저장하기
- 사용자 질문 입력하기
- 사용자 질문 내용과 유사한 요약 판결문 데이터들 가져오기
- 요약 판결문의 원본 찾기
문제는 5번 과정에서 발생했습니다.
찾고자 하는 판례명을 입력하면, 분명히 존재하고 있는 데이터임에도 불구하고 None 값을 반환했습니다.
원본 코드를 봤을 때, 분명히 논리 상으로 문제가 없어 보였습니다.
문제가 있다면 그것은 '문자열 입력 및 처리' 방면에서 발생한 거라 생각하고 디버깅에 착수했어요.
문제의 원인은 '문자열 정규화(Unicode string Normalization)'에 있었습니다.
같은 UTF-8 유형의 동일해 보이는 문자열이더라도, 문자열 정규화 방식에 따라 컴퓨터 인식 값이 달라지더라구요.
참고로 문자열 정규화 방식에는 아래와 같은 유형들이 있습니다.
- NFC (Normalization Form C, 가장 흔한 방식) : 완성형으로 변환
- NFD (Normalization Form D) : 조합형으로 변환
- NFKC (Normalization Form KC) : 호환성을 고려한 완성형으로 변환
- NFKD (Normalization Form KD) : 호환성을 고려한 조합형으로 변환
문자열 정규화를 고려해서 'input 값으로 입력한 판례명'과 '판례명 파일 이름'을 모두 NFC로 변환시켰습니다.
수정한 코드는 아래와 같습니다.
import unicodedata as ud
def find_exact_case(case_number: str) -> str:
for doc in docs:
doc_source = doc.metadata["source"].split('/')[-1]
# normalize utf-8 string with NFC type
doc_source = ud.normalize('NFC', doc_source)
if doc_source.find(case_number) != -1:
return doc.page_content
if __name__ == '__main__':
# '2021노139' 판례 원본 찾기
print(find_exact_case('2021노139')) # 해당 판례 원본 내용 출력
위와 같은 과정을 거쳤더니 5번 과정을 성공적으로 수행할 수 있게 되었습니다!
만약 코드 리팩토링을 하게 된다면, 아예 처음부터 파일명을 NFC 유형으로 일괄 정규화시켜도 좋을 것 같네요 :)
# langchain 15번 예제 코드 수정
langchain 15번 예제 코드는 'LangChain 라이브러리 + CodeLlma 연동 코드'였습니다.
CodeLlma는 메타에서 오픈 소스로 공개한 코드 생성 AI인데요.
아무래도 AI이기 때문에 GPU로 동작시키는 것이 CPU에 비해 훨씬 빠릅니다.
문제는 CodeLlma 실행에 꼭 필요한 'LlamaCPP 모듈(GPU ver.)' 을 설치할 때 발생했습니다.
살짝 수업 관련 TMI를 남기자면요...
저희는 수업에서 Colab을 씁니다.
커리큘럼 중 LLM 단원에 진입하면 'Colab Pro +'를 지원받을 수 있어서 그걸 사용하고 있어요.
단, Colab 중 제일 좋은 사양인 'Pro +'를 사용해도 컴퓨팅 할당 가능 자원이 무제한은 아니라는 점.... 꼭 기억하세요....!
따라서 사용하지 않을 때는 GPU 연결 해제하는 것을 권장합니다!
2024.08 기준 코랩에서 'LlmaCPP 모듈(GPU ver.)' 설치가 안 되시는 분들은 아래 버전으로 설치하는 것을 추천해요.
# 문제가 되었던 버전은 llama_cpp_python-0.2.86
# 수정 코드의 버전은 0.2.7
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python==0.2.7
2024.08 시기 코랩에서 'LlmaCPP (0.2.86 ver.)'을 설치하면 파이썬 모듈을 빌딩하는 하위 과정 속에서 에러가 나더라구요.
0.2.7 버전으로 설치하시면 2024.08 시기의 코랩 환경과 호환이 잘 되어서 성공적으로 CodeLlma 모델을 동작시킬 수 있습니다!
# Conv2DTranspose 동작 이해를 도울 수 있는 자료 찾기
'Conv2DTranspose 기능'은 이미지 생성 코드에서 자주 볼 수 있는 메서드 중 하나입니다.
Conv2DTranspose 메서드는 이미지 분류에서 많이 볼 수 Conv2D와 반대 방향으로 동작합니다.
또한 Conv2D 연산을 거치면 Output 크기가 줄어들지만, Conv2DTranspose는 크기가 줄어들지 않고 유지됩니다.
결과적으로만 보면 어려워 보이지 않습니다!
하지만 늘 이야기했던 것처럼 과정이 제일 중요하지요.
(+ 과정에 충실하면 결과도 어느 정도 따라온다고 생각하는 편이거든요...^^)
Conv2DTranspose 메서드 동작 과정을 더 깊게 탐구한 후, 이해하는 데에 있어서 필요한 자료를 사람들에게 공유하고 싶었습니다.
Conv2DTranspose는 아래와 같은 방식으로 동작합니다.
1. 커널 값 아래와 같은 형태로 변환시킵니다. 이 과정 때문에 Transpose라는 말이 붙었습니다.
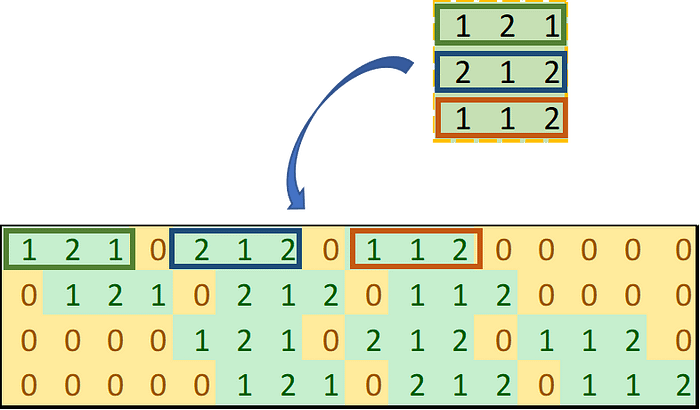
2. 인풋 행렬을 벡터 형태로 쭉 펴줍니다.

3. 위 과정에서 변환시킨 것들을 곱합니다. 그러면 컨볼루션 연산한 값이 나옵니다.

4. 1번에서 얻은 '변환 형태의 커널'과 3번에서 얻은 '컨볼루션 연산 결과 벡터'를 곱해줍니다. 그러면 최종적으로 Conv2dTranspose 연산을 취한 값을 얻을 수 있습니다.

짜잔~ 일반적인 컨볼루션 연산과 다르게 output에서도 input 크기가 유지되었지요?
이러한 특성 때문에 이미지 생성 모델에서 많이 쓰인답니다!
이 과정을 이해할 때, 하단 포스팅의 도움을 많이 받았어요.
정말 좋은 자료라서 수업 시간에 다른 분들께도 공유했답니다!
강사님께서 코드 구현과 함께 근본 원리 설명이 나타나 있는 점이 마음에 든다고 칭찬하셔서 기분이 좋았어요 :)
유익한 자료인데 저만 보기에는 아깝잖아요~~~!!!
👉 Conv2DTranspose 동작 원리 참고 포스팅 링크 :

어딘가에 기여를 한다는 건 정말 뿌듯하고 즐거운 일이에요!
다음에는 강사님께서 말씀하신 것처럼 오픈소스에도 기여해 봐야겠습니다 ^_^
특히... TensorFlow 한국어 공식 문서가 영어 문서에 비해 업데이트 속도가 느리더라구요.
그것부터 먼저 시도해 봐야겠습니다!
● 개선
이번 주말에는 밑시딥 1권으로 역전파를 복습했습니다!
단순히 읽는 것만 하면 금방 끝나겠지만, 코드까지 동작시켜 봐야 진정한 공부라 생각해서 시간을 꽤 투자하고 있는 중입니다 :)
# 계산 그래프(computational graph)
계산 그래프(computational graph)는 계산 과정을 그래프 형태로 표현한 것입니다.
그래프는 노드와 엣지로 구성되어 있어요.
알고리즘 공부를 한 번이라도 한 적이 있다면 노드와 엣지가 무엇인지 쉽게 알 수 있을 거라 생각합니다.
수학에서 의미하는 그래프와 다르게, 컴퓨터 공학에서 말하는 그래프는 아래와 같은 형태로 생겼어요.
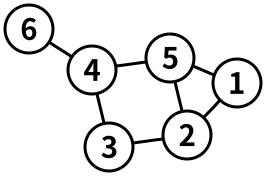
동그란 것을 '노드(node)'라 부르고, 선을 '엣지(edge)'라 부릅니다.
계산 과정을 그래프 형태로 표현해 보면 어떻게 생겼을까요?
'{ (사과의 개수) X (사과의 가격) + (귤의 개수) X (귤의 가격) } X 소비세' 라는 공식을 계산 그래프로 표현해 볼까요?
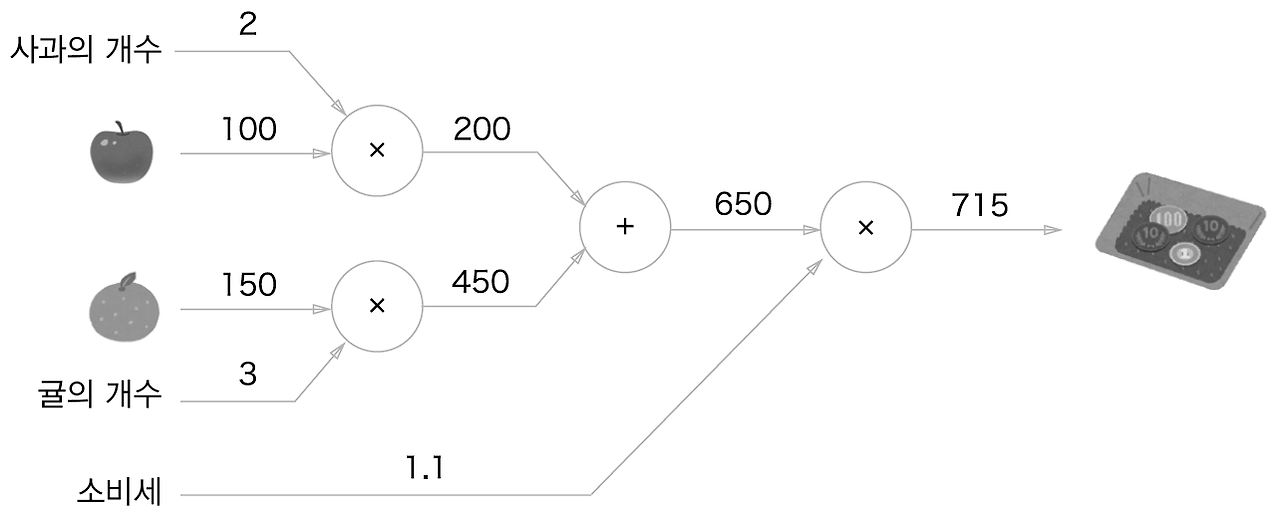
위와 같이 표현할 수 있습니다.
계산 그래프를 사용하면 역전파를 수행하기 쉽다는 장점이 있어요!
역전파를 사용하면 수치 미분(numerical differentiation)을 사용하지 않고도 미분값을 빠르고 쉽게 계산할 수 있습니다 :)
아래에는 역전파 계산 시 사용되는 코드 예시들입니다.
사용 라이브러리는 이렇습니다.
import numpy as np
from typing import TypeVar, Tuple
import numpy.typing as npt
# 층 단순 연산 구현 (합 & 곱)
# user defined type hint
IntFloat = TypeVar('IntFloat', int, float)
class AddLayer:
def __init__(self):
pass
def forward(self, x: IntFloat, y: IntFloat) -> IntFloat:
out = x + y
return out
def backward(self, dout: IntFloat) -> Tuple[IntFloat]:
dx = dout * 1
dy = dout * 1
return (dx, dy)
class MulLayer:
def __init__(self):
self.x: IntFloat = None
self.y: IntFloat = None
def forward(self, x: IntFloat, y:IntFloat) -> IntFloat:
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout: IntFloat) -> Tuple[IntFloat]:
dx = dout * self.y
dy = dout * self.x
return (dx, dy)
# 활성화 층 연산 구현 (ReLU & Sigmoid)
class Relu:
def __init__(self):
self.mask: npt.NDArray[np.bool_] = None
def forward(self, x: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
dout[self.mask] = 0
dx = dout
return dx
class Sigmoid:
def __init__(self):
self.out: npt.NDArray[np.float64] = None
def forward(self, x: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
dx = dout * (1.0 - self.out) * self.out
return dx
# Affine & Softmax 층 연산 구현
def softmax(a: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
# Using variable c to prevent overflow value.
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
def cross_entropy_error(y: npt.NDArray[np.float64], t: npt.NDArray[np.int32]) -> np.float64:
delta = 1e-7
return -np.sum(t * np.log(y + delta))
class Affine:
def __init__(self, W: npt.NDArray[np.float64], b: npt.NDArray[np.float64]):
self.W: npt.NDArray[np.float64] = W
self.b: npt.NDArray[np.float64] = b
self.x: npt.NDArray[np.float64] = None
self.dW: npt.NDArray[np.float64] = None
self.db: npt.NDArray[np.float64] = None
def forward(self, x: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx
class SoftmaxWithLoss:
def __init__(self):
self.loss: npt.NDArray[np.float64] = None
self.y: npt.NDArray[np.float64] = None
self.t: npt.NDArray[np.int32] = None
def forward(self, x: npt.NDArray[np.float64], t: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]:
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout: np.float64 = 1) -> npt.NDArray[np.float64]:
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx
# 역전파를 적용하여 AI 학습시키기
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grad = network.gradient(x_batch, t_batch)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
오늘 첨부한 코드들만으로 실제 동작하는 것을 보는 건 어렵습니다.
왜냐하면 라이브러리 버전, 추가 모듈 등을 비롯하여 개발 환경이 많이 다를 거니까요.
의사 코드(pseudo-code) 역할로 첨부했다고 생각하시면 좋을 것 같습니다 :)

자, 이제 자고 일어나서 수업 들으러 갈 준비를 또 해야겠어요!
다음에 배울 내용들도 힘내서 공부해 보겠습니다~!
+) 부족한 부분이 있으면 댓글로 말씀해 주세요! 겸허한 마음으로 더 공부하겠습니다.
'활동 > SK네트웍스 Family AI 캠프 2기' 카테고리의 다른 글
| SK네트웍스 Family AI 캠프 2기 : 15th week (8월 4주차) (3) | 2024.08.26 |
|---|---|
| SK네트웍스 Family AI 캠프 2기 : 14th week (8월 3주차) (0) | 2024.08.19 |
| SK네트웍스 Family AI 캠프 2기 : 12th week (8월 1주차) (1) | 2024.08.05 |
| SK네트웍스 Family AI 캠프 2기 : 11th week (7월 4주차) + 7월 회고 (0) | 2024.07.29 |
| SK네트웍스 Family AI 캠프 2기 : 10th week (7월 3주차) (5) | 2024.07.21 |



